Intro
Automating infrastructure provisioning with Terraform is nothing for many, but to truly harness IaC power, seamless integration with CI/CD pipelines is key. In this guide, we'll walk you through the process of setting up and running your Terraform configurations within GitLab CI from an GitHub imported repo. This powerful combination not only ensures consistent deployments but also brings version-controlled infrastructure management to the forefront of your development workflow.  This is the first topic of my terraform pipelines for dummies series that covers pipelined deployments in GitLab, GitHub Actions, AzureDevOps, AWS Catalyst and GCP Cloud build. A beautiful excuse to learn CI/CD for Infra bros while having fun.
This is the first topic of my terraform pipelines for dummies series that covers pipelined deployments in GitLab, GitHub Actions, AzureDevOps, AWS Catalyst and GCP Cloud build. A beautiful excuse to learn CI/CD for Infra bros while having fun.
I. Importing a GitHub Repo to GitLab
If you have your source repo stored in GitHub (i.e github.com/brokedba/terraform-examples )
There are two ways to do it :
Option1: Import from GitHub using GitLab UI
In your GitLab portal, click new project and select “import project” option

Once you select the import project option, hit "Repository by URL" and fill the source/target repo details
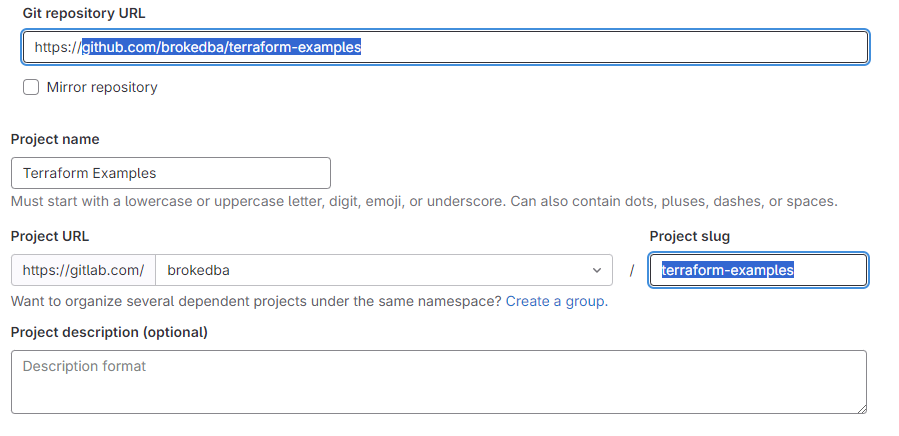
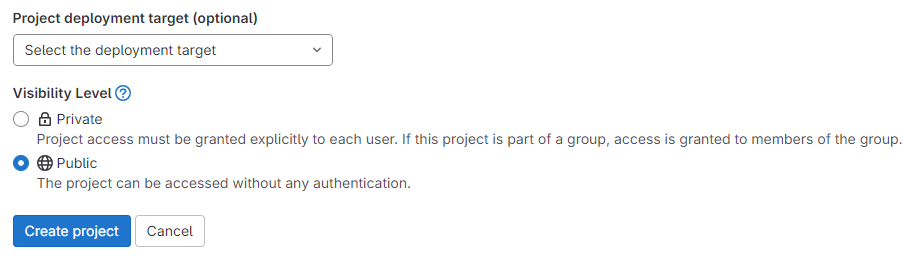
Choose the visibility of the imported project (repo), and hit create project.
Note You could also import the repo by authorizing GitLab to access your GitHub in one click

- Option2: Import using git CLI
Clone the GitHub repository on your shell
$git clone https://github.com/brokedba/terraform-examples.gitAdd an ssh public key to your Gitlab under GitHub Profile> preference>SSH Key
Test your connection with your Gitlab from your terminal by specifying the SSH private key
brokedba@brokdba:~$ssh -i ~/.ssh/id_rsa_gitlab -T git@gitlab.comWelcome to GitLab, @brokedba!Create a New GitLab Project in GitLab GUI same as the git repo name “terraform-examples”
Add GitLab as a Remote repo: adjust the below with your GitLab Namespace
$
$git remote add origin git@gitlab.com/{Namespace}/terraform-examples.gitPush to GitLab: this will ask for your Gitlab Credentials
$ GIT_SSH_COMMAND="ssh -i ~/.ssh/id_rsa_gitlab" git push -u origin main
remote: Resolving deltas: 100% (733/733), done.
To git@gitlab.com:brokedba/terraform-examples.git
* [new branch] main -> main
Branch main set up to track remote branch main from origin.
II. CI/CD pipeline Authentication Variables
Now that our repo is imported we’ll set the necessary variables for our terraform pipeline.
Our target platform will be Oracle Cloud.
Under the Project, Click Settings > CI/CD > Variables > Expand > Add Variable.
Under "Variables", click "Expand" and add your the Authentication variables

For our deployment we’ll need to set below variables. GitLab equivalent for secrets is masked variables
TF_VAR_tenancy_ocid : Masked
TF_VAR_private_key_path: Masked
TF_VAR_fingerprint: Masked
TF_VAR_user_ocid: Masked
TF_VAR_compartment_ocid: Masked (where to create the resource )
TF_VAR_region
TF_VAR_ssh_public_key: variable of type file, for the vm to be deployed (to contain long text)
TF_VAR_gitlab_access_token: this token authorizes runners to interact with GitLab. Unlike GitHub, where authentication is automatic through GITHUB_TOKEN, GitLab requires manual setup.
III. Creating the Terraform pipeline in GitHub
The GitLab CI/CD pipeline config is controlled by a .gitlab-ci.yml file, similar to GitHub Workflow.
We need to create ci file in the root directory of our repo based on a template called Terraform.latest.gitlab-ci.yml

Description of the GitLab-ci content
Each gitlab-ci template allows the abstraction of actions depending on its type. In our case base.gitlab.ci extends all terraform workflow stages. This is different than GitHub actions, with shorter code footprint . \
1) Generic section contains the include which loads templates and the variables

TF_ROOTrepresents the working directory where our terraform config files reside in my repo.
I many deployments, but the variable can take any subdirectory I want (i.e launch-instance).
Note: the SAST template in the picture was removed later from my include please do the same.
2) Terraform workflow section where our terraform deployment tasks are performed (init, plan, deploy)

After we declared the stage names and defined the same in a sequence as described below.fmt– for formatting the Terraform config.validate– validation of code.build– run terraform plandeploy– executes terraform apply command. Then save the state file as an artifactcleanup– load the artifact (state file) and destroy the resource.
Each stage uses the keyword “extends” with .terraform:* that references a function in the template
VI. Executing the Terraform pipeline
Now that we have both the project (repo), the variables, and the pipeline defined let’s run it and monitor the workflow.
Go to your project> build > Pipeline and click Run Pipeline

DEPLOY: Both validate & build (tf plan) stages are now done, the pipeline waits for a manual deploy

Once run, you can check the logs while our web server is being deployed in Oracle Cloud platform
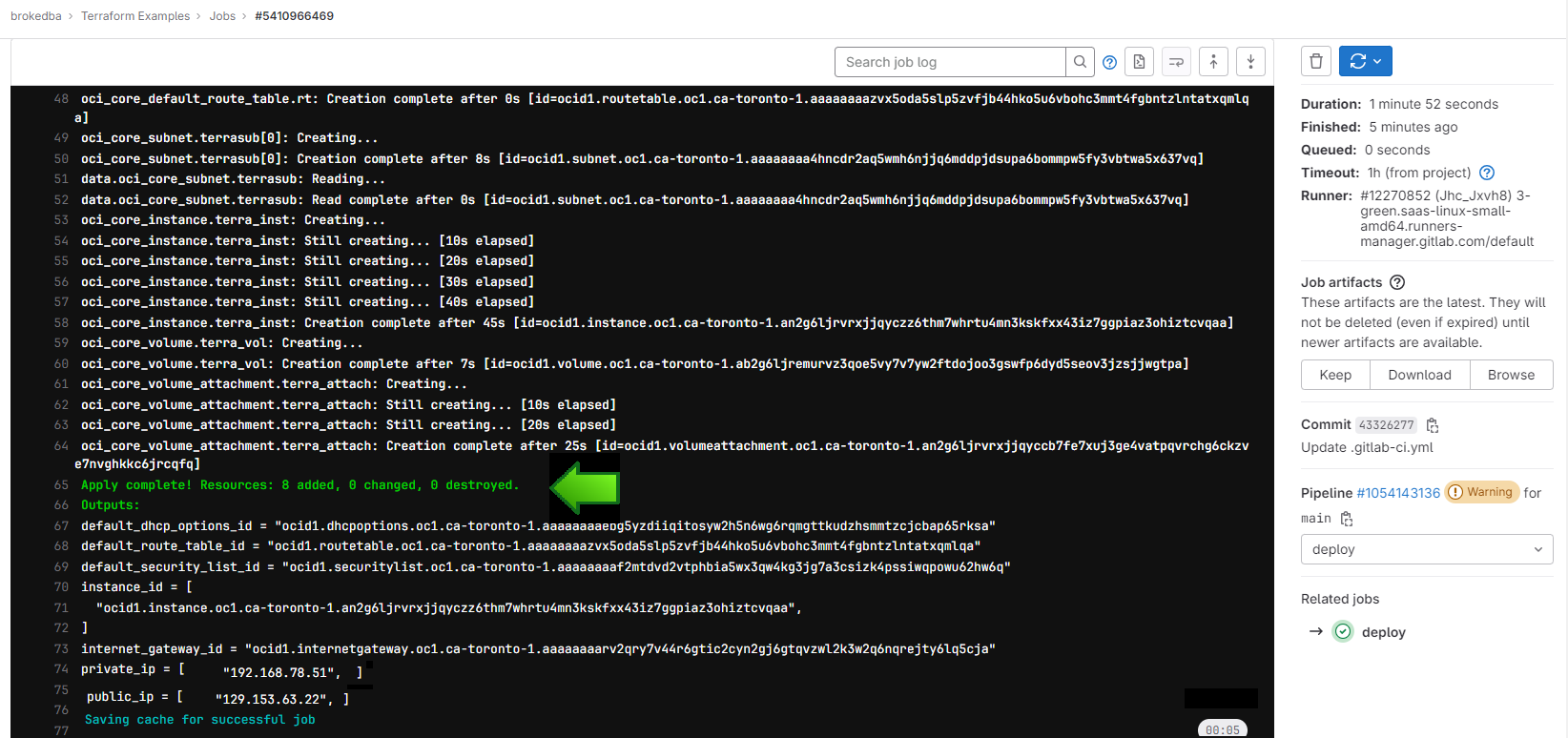
If we check the console, we’ll see that the webserver is now up and running, ready to take requests

DESTROY: After a successful deploy, all looks good, we can now cleanup by tearing down our resources
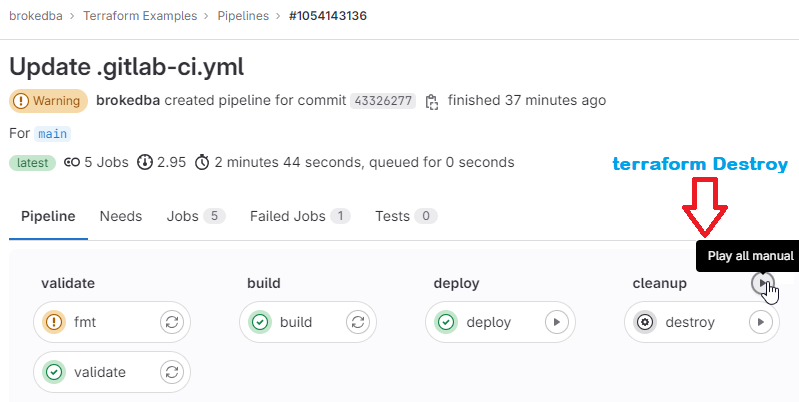
Notice how the cleanup job reused the state file, loaded from the artifact to destroy the webserver
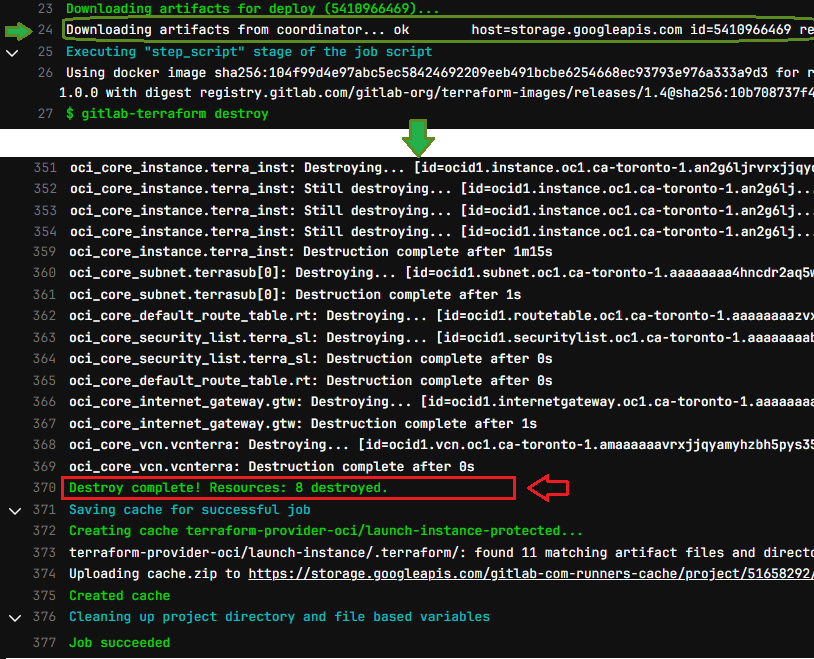
DESTROY: After a successful deploy, all looks good, we can now cleanup by tearing down our resources
Notice how the cleanup job reused the state file, loaded from the artifact to destroy the webserver
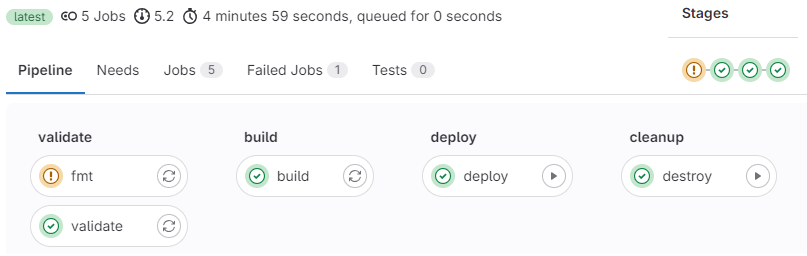
Final pipeline status
Once complete we can see the status and the time it took to finish the pipeline (fmt had just a minor warning)
V. GitLab Experience "Hits and Misses"
There are pros and tread offs about using GitLab over GitHub actions , here’s few to consider
Pros
GitLab is Open source but still more secure than GitHub.
I love how GitLab allows to pause a pipeline stage using the manual job option that GitHub doesn’t have.
GitLab has lot of templates available for different frameworks unlike GitHub actions 3rd-party marketplace
GitLab CI offers better reporting and auditing capabilities, for tracking/analyzing workflow performance.
Full of other features: child pipelines, dynamic pipeline generation, very flexible conditionals, composable pipeline definitions, security, merge trains, code review.
Cons
GitLab lacks GitHub’s massive popularity/support in the community (fewer blogs/StackOverflow posts).
GitLab supports only one CI workflow file (gitlab-ci.yaml) per repository, whereas GitHub allows multiple.
GitLab UI lacks Auto-refresh of the pipeline/job status forcing you to refresh the browser unlike in GitHub.
Conclusion:
We just showed a simple pipeline automating the whole workflow of a terraform deployment in OCI.
We also leveraged GitLab's unique manual job option for pausing pipeline stages which is rare elsewhere.
GitLab's singular approach relies on a rich built-in template library instead of a public Market place.
I tried to share few bits in terms of experience but there are tons of articles comparing GitLab&GitHub.
My demo didn’t cover event triggers via rules(CI_PIPELINE_SOURCE), but you can learn more here.
I also used artifacts to save a state file but it’s recommended to use GitLab managed remote state instead
Hope this helps , Next I’ll dive into GitHub Actions terraform Multicloud pipelines using OIDC.