Intro
I didn’t anticipate to have a series of posts around ZDM, but I had few issues that were worth sharing so here I am. This post will describe what caused a failure of an online physical migration ExaCC right at the Data guard configuration phase. The good thing about ZDM, is as soon as any detected issue is fixed manually, the resume job action will get you going which is the perfect design for a migration solution.
1. My ZDM environment
ZDM: 21.3 build
| Property | Source | Target |
| RAC | NO | YES |
| Encrypted | NO | YES |
| CDB | NO | YES |
| Release | 12.2 | 12.2 |
| Platform | On prem Linux | ExaCC |
Prerequisites
All the prerequisites related to the ZDM VM, the Source and Target Database system were satisfied before running the migration
Responsefile
Prepare a responsefile for a Physical Online Migration with the required parameters.The parameters themselves are not important in our case. I will just point out that ZDM 21.3 now supports Data Guard Broker configuration
$ cat physical_online_demo.rsp | grep -v ^#
TGT_DB_UNIQUE_NAME=TGTCDB
MIGRATION_METHOD=ONLINE_PHYSICAL
DATA_TRANSFER_MEDIUM=DIRECT
PLATFORM_TYPE=EXACC
ZDM_USE_DG_BROKER=TRUE
...
Run ZDMCLI Eval command
- The eval command successfully ran all prechecks to ensure migration readiness, so we’re good to go
$ZDM_HOME/bin/zdmcli migrate database –sourcedb SRCDB \ -sourcenode srcHost -srcauth zdmauth \ -srcarg1 user:zdmuser \ -targetnode tgtNode \ -tgtauth zdmauth \ -tgtarg1 user:opc \ -rsp ./physical_online_demo.rsp –eval
Run migration until the DG config
Run migration until the DG config
Now, It’s time to run the migrate command with the -pauseafter ZDM_CONFIGURE_DG_SRC because the goal is to stop when the replication is configured in order to resume the full migration a later time.
$ZDM_HOME/bin/zdmcli migrate database –sourcedb SRCDB \ -sourcenode srcHost -srcauth zdmauth \ -srcarg1 user:zdmuser \ -targetnode tgtNode \ -tgtauth zdmauth \ -tgtarg1 user:opc \ -rsp ./physical_online_demo.rsp –ignore ALL -pauseafter ZDM_CONFIGURE_DG_SRC
Querying job status
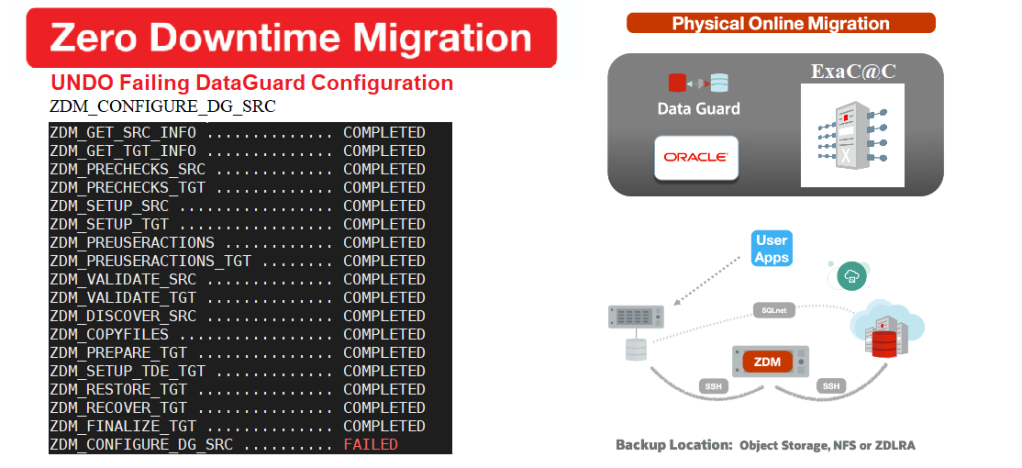
As you can see even if the standby was prepared successfully the Data guard configuration failed.
$ zdmservice query job –jobid 2
zdmhost.domain.com: Audit ID: 39
Job ID: 2
User: zdmuser
Client: zdmhost
Job Type: "MIGRATE"
Current status: FAILED
Result file path: "/u01/app/oracle/zdmbase/chkbase/scheduled/job-2-*log" ...
Job execution elapsed time: 1 hours 25 minutes 41 seconds
ZDM_GET_SRC_INFO .............. COMPLETED
ZDM_GET_TGT_INFO .............. COMPLETED
ZDM_PRECHECKS_SRC ............. COMPLETED
ZDM_PRECHECKS_TGT ............. COMPLETED
ZDM_SETUP_SRC ................. COMPLETED
ZDM_SETUP_TGT ................. COMPLETED
ZDM_PREUSERACTIONS ............ COMPLETED
ZDM_PREUSERACTIONS_TGT ........ COMPLETED
ZDM_VALIDATE_SRC .............. COMPLETED
ZDM_VALIDATE_TGT .............. COMPLETED
ZDM_DISCOVER_SRC .............. COMPLETED
ZDM_COPYFILES ................. COMPLETED
ZDM_PREPARE_TGT ............... COMPLETED
ZDM_SETUP_TDE_TGT ............. COMPLETED
ZDM_RESTORE_TGT ............... COMPLETED
ZDM_RECOVER_TGT ............... COMPLETED
ZDM_FINALIZE_TGT .............. COMPLETED
ZDM_CONFIGURE_DG_SRC .......... FAILED
ZDM_SWITCHOVER_SRC ............ PENDING
ZDM_SWITCHOVER_TGT ............ PENDING
ZDM_POST_DATABASE_OPEN_TGT .... PENDING
ZDM_DATAPATCH_TGT ............. PENDING
ZDM_NONCDBTOPDB_PRECHECK ...... PENDING
ZDM_NONCDBTOPDB_CONVERSION .... PENDING
ZDM_POST_MIGRATE_TGT .......... PENDING
ZDM_POSTUSERACTIONS ........... PENDING
ZDM_POSTUSERACTIONS_TGT ....... PENDING
ZDM_CLEANUP_SRC ............... PENDING
ZDM_CLEANUP_TGT ............... PENDING
Troubleshooting
We can check the result file to investigate the error, but I always like to dig into the specific ZDM_BASE logs hosted locally in specific src/target nodes. Here it’s in the source server (see below)
--- On the source
$ cd $ORACLE_BASE/zdm/zdm_SRCDB_$jobID/zdm/log
$ tail -f ./zdm_configure_dg_src_5334.log
[mZDM_Queries.pm:6136]:[DEBUG] None of DB_CREATE_FILE_DEST,
DB_CREATE_ONLINE_LOG_DEST_%,DB_RECOVERY_FILE_DEST is configured for SRCDB
[mZDM_Queries.pm:*]:[DEBUG] Will be running following sql as user: oracle:
[mZDM_Queries.pm:3377]:[ERROR] unable to created undo tablespace UNDOTBS2
CREATE UNDO TABLESPACE UNDOTBS2 DATAFILE '/oradata/undotbs2.dbf' SIZE 98300M
AUTOEXTEND ON
*
ERROR at line 1: ORA-01144: File size (12582400 blocks)
exceeds maximum of 4194303 blocks
Looks like ZDM wanted to create a large second UNDO tablespace in the source, with one Data file that’s greater than 32GB. But why does ZDM need to create a second undo tablespaces in source DB.
Why is a second UNDO needed ?
In the 21.3 release Note, you’ll find that:
`ZDM adds UNDO tablespaces to the production database to match target instance count, if source database has fewer instances`
Hence, an ExaCC 2 node RAC will require ZDM to create a 2nd UNDO tablespaces in the source
What really Happened
Ok so far it makes sense, but what really caused our failure is that ZDM tried to create a 2nd UNDO with a datafile of 98GB. Let’s check our source UNDO tablespace to learn more.
SRCDB> @check_tbs UNDO
TABLESPACE_NAME ALLOCATED_MB MAX_SIZE_MB FREE_PCT ---------------- ------------ ------------ ----------
UNDO 98301 97681 99FILE_NAME Size ---------------------- ------ /oradata/undo_1.dbf 32GB /oradata/undo_2.dbf 32GB /oradata/undo_3.dbf 32GB
Root cause:
It turns out ZDM was trying to create a second UNDO tablespace based on the total size of the tablespace using one datafile which would have not triggered an error if the total tablespace size was lower than 32GB.
Solution: Recreate as Bigfile
Although an ER has already been filed by Oracle support after I told them about it, I still needed a quick fix.
So here’s what I did: (On Source DB)
Create a new dummy UNDO tablespaces (Ideally same size as the original UNDO)
SQL> CREATE UNDO TABLESPACE UNDOTBS3 DATAFILE '/oradata/undotbs3.dbf' SIZE 10G; SQL> ALTER SYSTEM SET UNDO_TABLESPACE = UNDOTBS3 SCOPE=BOTH;
SQL> SELECT tablespace_name, status, count(*) from dba_rollback_segs
group by tablespace_name, status;
TABLESPACE_NAME STATUS COUNT(*) ------------------------------ ------------ ---------- UNDOTBS3 ONLINE 10 UNDO OFFLINE 24 <--- ready to be droppedWhen the old Undo tablespace is of status OFFLINE, drop it
SQL> DROP TABLESPACE UNDO including contents and datafiles;
Now recreate the old UNDO using one Bigfile datafile
CREATE BIGFILE UNDO TABLESPACE UNDO DATAFILE '/oradata/undotbs.dbf' SIZE 90G;
ALTER SYSTEM SET UNDO_TABLESPACE = UNDO SCOPE=BOTH;Drop the dummy UNDO tablespace
SQL> DROP TABLESPACE UNDOTBS3 including contents and datafiles;
Note: I have not named it UNDOTBS2 because ZDM will use it when creating the second UNDO later.
Resume the job
Now that we have one bigfile in the UNDO tablespace we can resume the ZDM job and the phase will not complain
$ zdmservice resume job –jobid 2
$ zdmservice query job –jobid 2
...
ZDM_CONFIGURE_DG_SRC .......... COMPLETED
ZDM_SWITCHOVER_SRC ............ PENDING
ZDM_SWITCHOVER_TGT ............ PENDING
ZDM_POST_DATABASE_OPEN_TGT .... PENDING
ZDM_DATAPATCH_TGT ............. PENDING
ZDM_NONCDBTOPDB_PRECHECK ...... PENDING
ZDM_NONCDBTOPDB_CONVERSION .... PENDING
ZDM_POST_MIGRATE_TGT .......... PENDING
ZDM_POSTUSERACTIONS ........... PENDING
ZDM_POSTUSERACTIONS_TGT ....... PENDING
ZDM_CLEANUP_SRC ............... PENDING
ZDM_CLEANUP_TGT ............... PENDINGPause After Phase: "ZDM_CONFIGURE_DG_SRC"
Tip:
Best way to avoid this issue is to convert the source UNDO into Big file in the first place .
Conclusion
- Although ZDM allows you to run one command to automate the entire migration you still need to troubleshoot issue that might occur here and there
- The automation with a resume option in case failure makes the process more reassuring to us DBAs
- Hope this will help anyone who runs into the same error to quickly fix it and go on with the migration
- On my next post I’ll be talking about another issue I faced which required a little hack, stay tuned
Thank you for reading
No comments:
Post a Comment