Intro
This is the last part of the OVM series where I will describe the backup package provided by oracle called ovm-bkp . Even if the Premier Support period has already ended (March, 2021) and OLVM is supposed to be the replacement, a lot of workloads are still running on OVM including new PCAs (Private Cloud Appliances).
The part that was lacking until recently was a comprehensive solution to backup and restore the vms in the OVM platform. I am not saying it’s perfect nor equivalent to the GUI based service on vmware but it does the job at least, especially since OVM has zero license cost.
ovm-bkp utilities
Is a package allowing to get a crash-consistent backup of a running Virtual Machine and share it to external systems like Storages (NFS) or Media Server. Below figure depicts the backup options provided by ovm-bkp utility
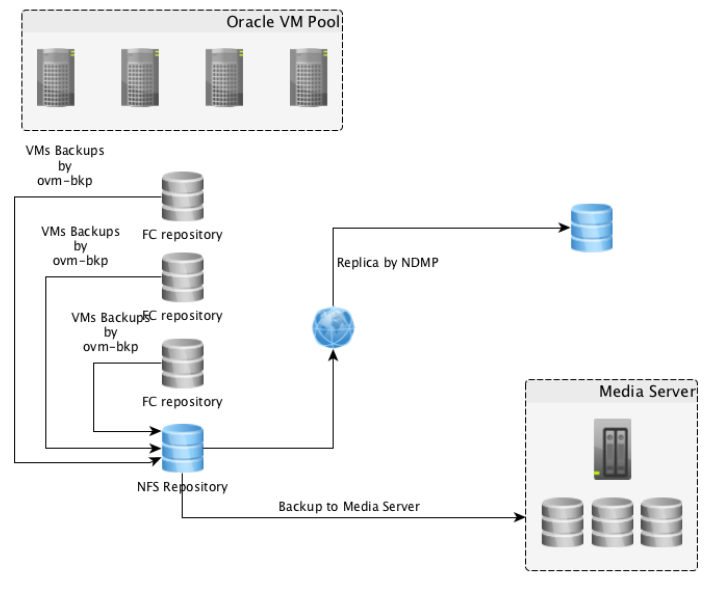
All the backup operations will be executed starting from OVM Manager server managing the OVM Pool; the entire solution is based on scripts and OVMMCLI interface.
What you need to know
Requirements
"ovm-bkp" supports OVM 3.4 and must be installed on OVM Manager machine to function
OVM Resources (OVM Pools, VMs, Repositories ) must not contain a space in their name (must be renamed if so)
Online backups of a Running VM can be taken only if vdisks reside on OCFS2 repositories (iSCSI or Fiber Channel links)
Backup of running VMs with disks on NFS repositories won’t be possible without the vm being shut down first which ovm-bkp will do silently (without warning).
Reason: hot-clone feature relies on ocfs2 ref-link option that only works with iSCSI/ FC storage links
Destination repository however can be either NFS or OCFS2
To make a backup work on a vm hosted in an NFS repo a little tweak must done for the backup script
Backups will contain only virtual-disks. Physical disks are out of scope and must be handled separately
Installation and configuration
rpm package
[root@em1 ~]# yum -y localinstall ovm-bkp-1.1.0e-20201012.noarch.rpm
Configure the Oracle VM Manager access for "ovm-bkp" utilitie
This script will generate an ovm backup configuration file that contains OVM metadata like the UUID and OVMCLI access info
[root@em1~]# /opt/ovm-bkp/bin/ovm-setup-ovmm.sh
log as OVM admin user /password
New configuration file /opt/ovm-bkp/conf/ovmm/ovmm34.conf created:
------------------------
# Oracle VM Manager Command Line Interface User
ovmmuser=admin
# Oracle VM Manager Command Line Interface Password - Encrypted
ovmmpassenc=U2FooGVkX1/OvXXXXXXXXXXXXXX
# Oracle VM Manager Host
ovmmhost=em1
# Oracle VM Manager CLI Port
ovmmport=10000
# Oracle VM Manager UUID
ovmmuuid=0004fb000001XXXXXXXXXXXXXXX
Configure virtual machine backup
./ovm-setup-vm.sh VMname (d=days| c=counts) [target_Repository] disktoexlude(X,X)
[root@ovm-manager01 bin]# /opt/ovm-bkp/bin/ovm-setup-vm.sh My_VM c1 vmdata_Repo --- Target repository where the vm is stored and the backup will be saved
New configuration file for VM My_VM has been created at
/opt/ovm-bkp/conf/vm/My_VM-0004fb000006000030121f9302f49f44.conf:
# Oracle VM Pool
ovmpool=OVM-Lab
# VM Details
vmname=My_VM
vmuuid=0004fb000006000030121f9302f49f44
vdiskstoexclude=
# Retention to Apply
retention=c1
# Target Repository
targetrepo=vmdata_repo
Backup steps
Collect required information (VM name, id and configuration).
Create a dedicated "Clone Customizer" based on the info of the VM.
Create a clone of the VM on the same OCFS2 repository (using ocfs2-reference-link)
If "backup type" = "SNAP", it goes to step (4).
If "backup type" = "FULL", it moves the cloned vm to target Repo (NFS/OCFS2) defined in the config file.
If "backup type" = "OVA" , it creates an OVA file – based on the clone and saves it to the target Repo defined in the config file (under Assembly folder).
Move the cloned VM under folder "Unassigned Virtual Machine" on OVM Manager
o All "SNAP" and "FULL" backups will be displayed under "Unassigned Virtual Machines"
o Retention policy is applied and all backups that don’t satisfy it are deleted (unless they are flagged preserved)
Backup script
[root@em1]# /opt/ovm-bkp/bin/ovm-backup.sh <Vm name> <backup type> <preserve>
<backup_type> :
- FULL => will create a full vdisk backup on a further repository
- SNAP => will create an ocfs2 reference-link snapshot of the vm on the same Repo
- OVA => will create a packaged OVA file on a further repository
<preserve> "preserve": preserved backup will be ignored by the retention policy applied.
Below is a full backup that will not be preserved (checked by the retention policy on the next backup)
[root@em1]# /opt/ovm-bkp/bin/ovm-backup.sh My_VM FULL n
=================
Oracle VM 3.4 CLI
=================
=====================================================
Adding VM My_VM information to bkpinfo file /opt/ovm-bkp/bkpinfo/info-backup-My_VM-FULL-20210728-1316.txt
=====================================================
================================================
Creating Clone-Customizer to get VM snapshot.... <--1
================================================
=======================
Getting VM snapshot.... <--2
=======================
=====================
Backup Type: FULL....
=====================
=======================================================
Moving cloned VM to target repository .... <--3
=======================================================
=======================================================
Waiting for Vm moving to complete......10 seconds
...
Waiting for Vm moving to complete......800 seconds
=======================================================
=================================================
Renaming VM backup to gcclub.0-FULL-20210728-1316....
=================================================
===================================
Adding proper TAG to backup VM....
===================================
Guest Machine My_VM has cloned and moved to My_VM-FULL-20210728-1316 on repository vmdata_Repo <-- 4
Guest Machine My_VM-FULL-20210728-1316 resides under 'Unassigned Virtual Machine Folder'
Retention type is Redundancy-Based
Actual reference is: 20210728-1316
Latest 2 backup images will be retained while other backup images will be deleted!!!
======================================================
=======>> GUEST BACKUP EXPIRED AND REMOVED: <<========
======================================================
=============================================================
Based on retention policy any guest backup will be deleted!!!
=============================================================
====================================================================================
=====> Backup available for guest My_VM (sorted by date) : <====================
========================================================================================
= BACKUP TYPE == BACKUP DATE == BACKUP TIME == BACKUP NAME == PRESERVED ==
========================================================================================
= FULL == 20210718 == 0423 == My_VM-FULL-20210718-0423 == NO
= FULL == 20210725 == 0451 == My_VM-FULL-20210725-0451 == NO
Other commands
There are few other operations that can list, delete, and preserve backups. We will talk about the restore script separately
[root@em1]# /opt/ovm-bkp/bin/ovm-listbackup.sh vbox-bi
===============================================================================
=====> Backup available for guest vbox-bi (sorted by date) :
===============================================================================
= BACKUP TYPE == BACKUP DATE == BACKUP TIME == BACKUP NAME == PRESERVED ==
===============================================================================
= FULL == 20170829 == 1159 == vbox-bi-FULL-20170829-1159 == YES
= SNAP == 20180207 == 2030 == vbox-bi-SNAP-20180207-2030 == YES
= SNAP == 20180207 == 2031 == vbox-bi-SNAP-20180207-2031 == NO
Use ovm-delete.sh <backup name>
[root@em1]# /opt/ovm-bkp/bin/ovm-delete.sh My_VM-FULL-20210725-0451
Use ovm-preserve.sh <backup name> Y
[root@em1]# /opt/ovm-bkp/bin/ovm-preserve.sh vmdb01-SNAP-20210824 Y
Restore script
The script will restore the VM backup in an interactive fashion.
[root@ovm-manager01 bin]# /opt/ovm-bkp/bin/ovm-restore.sh My_vm
============================================================
Please choose the VM vm1 backup you want to restore:
============================================================
=======================================================
1) My_vm-FULL-20210305-0926 2) My_vm-SNAP-20210305-0936
=======================================================
Choice: -> 2
============================================================
===================================================================
Oracle VM Pool will be the same of the backup taken.
With backup type SNAP it means that this is an OCFS2 reflink of the
source VM and, as you know, OCFS2 repositories cannot be presented
to more than one Oracle VM Pool.
===================================================================
==================================================================
Refreshing repository – vmdata_Repo - to get updated information...
==================================================================
===================================================================
Here you can see the list of repositories where the restore can be
executed on Oracle VM Pool OVM-Lab.
Backup vm1-SNAP-20200304-1825 size is equal to 20 GB
Please choose the Oracle VM repository where to restore the backup
named My_vm-SNAP-20200304-1825:
===================================================================
=======================================================
1) vmdata_Repo - Free 4758 GB
=======================================================
Choice: –> 1
===================================================================
=======================================================================
WARNING: vNIC(s) HW-ADDR are still used by the source VM or by an other VM
WARNING: restored VM will use other vNIC(s) HW-ADDR
=======================================================================
================================================
Creating Clone-Customizer to get VM restored....
================================================
=======================================================
Restoring to target repository vmdata_Repo....
=======================================================
=======================================================
Waiting for Vm restore to be available......0 seconds
...
Waiting for Vm restore to be available......160 seconds
=======================================================
=======================================================
Deleting temporary CloneCustomizer created......
=======================================================
=======================================================
Addinv vNIC(s) using configuration of the source VM
vNic 1 on Network-Id: 0a0b3c00
=======================================================
=======================================================
Moving Vm My_vm-RESTORE-20200304-1842
to the Oracle VM Pool: OVM-Lab
=======================================================
Notice that the name of the restored vm will not be the same as the original but will have “Restore-date” appended to it.
My scripts
I had to write some on my own too, as there it is no way to list the vm backups and their configuration in a bulk mode. It can get very tedious to do your regular checks If you have 20 vms with multiple backups each. I now made them available in my github
Displays all repositories and their filesystem (NFS/OCFS), all attached vms (simple_name and UUID).
Note: run this from the ovm server and not from the ovmm.
[root@ovm-server02]# ./check_repo_vm.sh
====================================================================================
VMs for directory /OVS/Repositories/0004fb00000300005e228a81464525c4
Used_GB : 5.5T Free_GB: 2.4T Free_pct: 71%
====================================================================================
0004fb0000060000e15330805c08afd6 => OVM_simple_name = 'Mysqlvm'
0004fb00000600006d36f09c20f39584 => OVM_simple_name = 'DNS1_vm'
0004fb000006000078cdd427c9b38b3a => OVM_simple_name = 'wwweb'
List the current ovm-bkp setup (Per vm) in your ovm environment
[root@em1]# ./check_vm_bkp_config.sh | grep Myvm
List all backups that are currently stored for configured vms
[root@em1]# ./check_vm_backuplist.sh
Let’s say you have been asked to drop all backups for 3 or 4 vms that are to be decommissioned. This will generate the
drop script “drop_bkps.sh” for all the backups linked to those vms . You only need to put the vm names in the script string list
[root@em1]# vi drop_vm_backup.sh
#!/bin/bash
strings=(
Myvm1 # <----- change me
Myvm2 # <----- change me
myvm3 # <----- change me
)
for i in "${strings[@]}"; do
/opt/ovm-bkp/bin/ovm-listbackup.sh "$i"|awk -F' == ' '{print $3}'| cut -d ' ' -f 1 | grep "\S" | awk '{print "/opt/ovm-bkp/bin/ovm-delete.sh " $0}' #>> drop_bkps.sh
done
Same principle here, you only need to put the vms name in the script string list to display their backups. It’s faster
than grepping from my other script check_vm_backuplist.sh output and handy for 3-10 vms check.
Purge oldest reserved backups
Preserved backups will never be deleted but sometimes customers like to keep single monthly preserved backup for a vm for example. This script relies on a check_vm_backup.sh that you have to adapt with the list of vms you want to delete the old preserved backups from. Once run, it will generate delete_reserved_date.sh file that can be run to delete all redundant preserved backups (in crontab for example).
[root@em1 ~]# vi ./clean_reserved_bkp.sh
#!/bin/bash
/opt/ovm-bkp/bin/check_vm_backup.sh > backup_list-"`date +"%d-%m-%Y"`".log 2awk '!= "YES" {next} {s=$8; sub(/-FULL-.*/, "", s)} s == ps {print pval} {ps = s; pval="/opt/ovm-bkp/bin/ovm-delete.sh "$8}' backup_list-"`date +"%d-%m-%Y"`".log > delete_reserved_"`date +"%d%m%Y"`".sh 3chmod u+x delete_reserved_"`date +"%d%m%Y"`".sh 4delete_reserved_"`date +"%d%m%Y"`".sh
delete_reserved_"`date +"%d%m%Y"`".sh
cron entry :
0 2 1 * * /root/clean_reserved_bkp.sh
Conclusion
This will close this series dedicated to Oracle VM environment. Next time I talk about about Oracle virtualization it would be about the successor of OVM which is called OLVM that ditched xen for KVM (a fork of Open source Ovirt project). A very fresh and exciting technology that I can’t wait to explore.
Thank you for reading