 Intro
Intro
Beside Long term release benefits, upgrading to a multitenant 19c Database will allow to completely ease the way test environments are refreshed from production servers. Say Goodbye to complex & lengthy RMAN duplicate scripts and hello to remote cloning. Even better with refreshable clones, production data is now automatically updated. Many blogs were written about it like the one from Tim Hall, Franck Pachot(Poor man’s standby), or Oracle ACE peer Diana Robete. But I still found a little thing to add, as I used Oracle scheduler to automate the refreshes unlike the default available option (EVERY X Minutes).
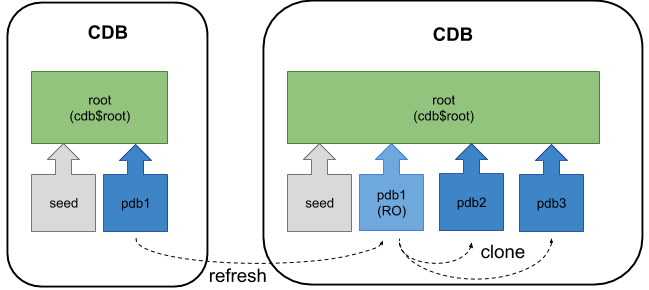
Options to refresh Test PDB from prod
A
PDB snapshot is a point-in-time copy of a PDB. Source PDB can be open read-only or read/write during snapshot creation. Copies can be sparse or full depending if storage system supports sparse clones or not.
Snapshots are created manually via SNAPSHOT clause or automatically using ‘EVERY interval’.
Restrictions:
Snapshot carousel requires ASM and ACFS filesystems which in my case is not present so I’ll pass.
Prerequisites
Similar to those of a hot, remote clone, here are the most common (19c) prerequisites.
User in the target database must have CREATE PLUGGABLE DATABASE privilege in root container.
Remote CDB uses local undo mode. Otherwise remote PDB must be opened in read-only mode.
Remote DB is in archivelog mode. Otherwise remote PDB must be opened in read-only mode.
If remote database is a PDB, the database link can point to the remote CDB using a common user, the PDB using a local or common user.
The user in remote database that the database link connects to must have the CREATE PLUGGABLE DATABASE privilege.
Target & remote databases must have same endianness.
Target & remote databases either have the same options installed, or the remote database must have a subset of those of the target database.
If the character set of the target CDB is AL32UTF8, remote DB can be any character set. If target CDB does not use AL32UTF8, the character sets of remote/local databases must match.
If the remote database uses TDE, the target CDB must be configured appropriately before attempting the clone. If not, the new PDB will only open in restricted mode.
Refresh Considerations
Refreshable Clone PDB must be closed during refresh
It must, also, be kept open Read Only the rest of the time to prevent out-of-sync changes
Other
-
A refreshable PDB can be changed to a non-refreshable PDB,
but not vice versa.
-
If source PDB is not available over DB link, archived redo
logs can be read from the optional REMOTE_RECOVERY_FILE_DEST location
parameter.
-
New datafiles added to the source PDB are automatically
created on the destination PDB. PDB_FILE_NAME_CONVERT parameter must be
specified for the conversion to happen.
Refreshable PDB demo
This scenario assumes db file parameters are not defined in the target environment. OS: Windows
NAME VALUE
-------------------- --------------------
db_file_name_convert
pdb_file_name_convert
db_create_file_dest
1- Create a common user in the source CDB with the required privileges where source pdb is “PSPROD”
SQL> Create user c##psprod_clone identified by welcome1 container=all;
SQL> Grant create session, create pluggable database to c##psprod_clone container=all;
2- Create a database link at the Target CDB using source TNS alias ‘SourceCDB’
SQL> create database link psprod_clone_link connect to c##psprod_clone
identified by welcome1 using 'SourceCDB';
3- Create a refreshable PDB clone using a manual refresh, plus few automatic refresh syntax examples.
-- Manual refresh mode.
CREATE PLUGGABLE DATABASE PSPDB_RO FROM PSPROD@psprod_clone_link
file_name_convert=('D:\ORACLE\DATA\','K:\ORACLE\CDB\PSPDB_RO\DATA\',
'H:\ORACLE\TEMP\','K:\ORACLE\PSPDB_RO\TEMP\')
REFRESH MODE MANUAL;
-- Automatically refresh every 60 minutes.
CREATE PLUGGABLE DATABASE PSPDB_RO FROM PSPROD@psprod_clone_link
REFRESH MODE EVERY 60 MINUTES;
-- Non-refreshable PDB.
-- Both below commands are functionally equivalent.
CREATE PLUGGABLE DATABASE PSPDB_RO FROM PSPROD@psprod_clone_link
REFRESH MODE NONE;
CREATE PLUGGABLE DATABASE PSPDB_RO FROM PSPROD@psprod_clone_link;
4- Perform a manual refresh . Syntax works for Post 12.2 from the root container
SQL> CONN / AS SYSDBA
ALTER PLUGGABLE DATABASE PSPDB_ro CLOSE IMMEDIATE;
ALTER PLUGGABLE DATABASE PSPDB_ro REFRESH;
ALTER PLUGGABLE DATABASE PSPDB_ro OPEN READ ONLY;
5- Check the last refresh time and SCN
SQL> SELECT last_refresh_scn,
cast(scn_to_timestamp(last_refresh_scn) as date) refresh_Time
FROM dba_pdbs WHERE pdb_name = 'PSPDB_RO' ;
LAST_REFRESH_SCN REFRESH_TIME
---------------- --------------------
17635452014 17-Dec-2021 16:48:17
Schedule a nightly refresh (4AM)
1- Create The refresh procedure
CREATE OR REPLACE PROCEDURE sys.psprod_refresh
AS BEGIN
EXECUTE IMMEDIATE 'ALTER PLUGGABLE DATABASE PSPDB_RO CLOSE IMMEDIATE';
EXECUTE IMMEDIATE 'ALTER PLUGGABLE DATABASE PSPDB_RO REFRESH';
EXECUTE IMMEDIATE 'ALTER PLUGGABLE DATABASE PSPDB_RO OPEN READ ONLY';
END;
/
2- Create the refresh JOB
BEGIN
DBMS_SCHEDULER.CREATE_JOB (
job_name => 'PSPROD_REFRESH_JOB',
job_type => 'STORED_PROCEDURE',
job_action => 'sys.psprod_refresh',
repeat_interval => 'freq=daily;byday=mon,tue,wed,thu,fri;BYHOUR=4; BYMINUTE=1',
auto_drop => FALSE,
enabled => TRUE,
comments => 'Automatic refresh of the prod PDB clone');
END;
/
SQL>@check_job PSPROD_REFRESH_JOB
JOB_NAME REPEAT_INTERVAL
------------------ --------------------------------------------------------
PSPROD_REFRESH_JOB freq=daily;byday=mon,tue,wed,thu,fri;BYHOUR=4; BYMINUTE
CREATE A CLONE FROM A REFRESHABLE PDB
You can see that File_name_convert works the same when creating a clone from a refreshable one
SQL> CREATE PLUGGABLE DATABASE PSDEV01 FROM PSPDB_RO
File_Name_convert=('K:\ORACLE\CDB\PSPDB_RO\DATA\','I:\ORACLE\CDB\PSDEV01\DATA\',
'K:\ORACLE\CDB\PSPDB_RO\TEMP\','I:\ORACLE\CDB\PSDEV01\TEMP\');
Conclusion
This was an example on how to automate the refresh of a PDB clone using a DBMS scheduler job that gives a better control on the frequency, instead of relying on the minutely refresh. Handy if you don’t like keeping an automatic refresh every X minutes and rather have it run once a day like a backup to avoid any unexpected maintenance.
Note: If you have the ORA-65345 error, "cannot refresh pluggable database". That means remote archive logs have been wiped from the source server and refresh should be adjusted to match the source backup retention.
Thank you for reading

 Intro
Intro
 Intro
Intro

 Intro
Intro